从原理上面来讲。去除虚假分支其实很简单。所以先简单说下理论。
虚假分支的混淆会在增加大量的if else分支。增加静态分析的复杂度。但是实际在动态执行的时候。很多if else实际都是没有执行的。所以去掉虚假分支其实就是删除掉那些没有执行到的代码块。那么我们只要知道目标函数中,哪些汇编代码执行了,并且记录下执行汇编的address。然后把这些汇编以外的代码全部标记为nop。然后再用ida反汇编看到的结果。就直接是去掉虚假分支的结果了。
下面我们从准备环境开始。
1、编译ollvm mkdir ~/ollvm/llvm-project-llvmorg-9.0.1/build-release
cd ~/ollvm/llvm-project-llvmorg-9.0.1/build-release
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang;clang++" ../llvm
ninja
2、配置ndk,使用ollvm的clang来进行编译apk 首先下载ndk,地址:https://developer.android.google.cn/ndk/downloads/
然后将ollvm编译好的cmake-build-release这个目录下的bin、lib、include三个目录拷贝到下载的ndk的目录~/ndk/toolchains/llvm/prebuilt/linux-x86_64/中。
然后修改我们的apk项目中的使用ndk的目录。否则会默认使用sdk中的ndk来编译。找到local.properties增加ndk.dir=/home/king/android-ndk-r21e
最后配置ollvm的参数在cpp/CMakeLists.txt中添加配置add_definitions("-mllvm -bcf -mllvm -bcf_loop=3")
然后这里碰到了一个问题。就是带上-mllvm -bcf这个参数。就会导致一直在gradle build中。这个实际上是ollvm的一个bug。由于我拉去的分支是没有修复这个bug的。所以需要根据这个地址的提交代码修改下就可以了https://github.com/obfuscator-llvm/obfuscator/pull/76
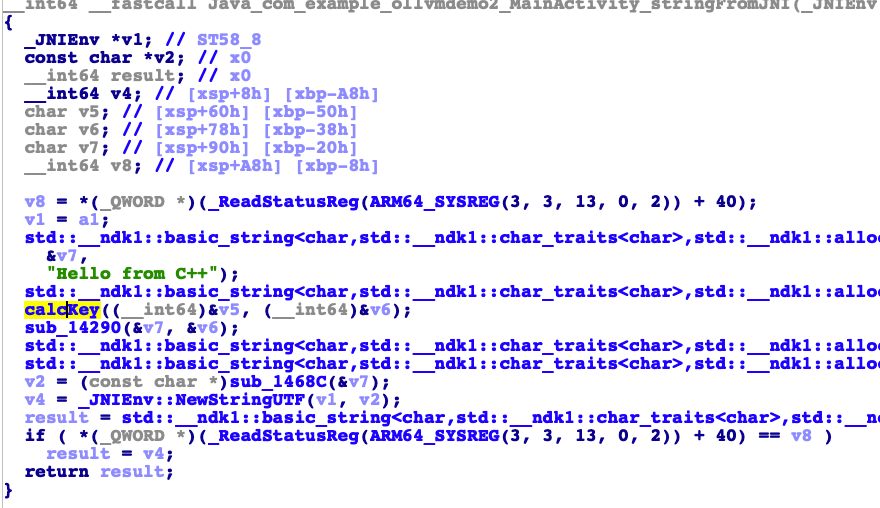
3、写个native-cpp的简单逻辑代码。用来作为反混淆的目标。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 extern "C" JNIEXPORT jstring JNICALLJava_com_example_ollvmdemo2_MainActivity_stringFromJNI( JNIEnv *env, jobject ) { std ::string hello = "Hello from C++" ; if (hello.length()>10 ){ hello="ceshi" ; }else if (hello.length()>30 ){ hello="ollvm" ; }else { hello="fla" ; } return env->NewStringUTF(hello.c_str()); }
编译后。使用ida打开native-lib.so。然后发现混淆没有起作用
这里编译使用的是clang++编译的。所以我们用clang++简单的测试一下混淆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> int main (int argc,const char ** argv) std ::cout << "Hello, World!" << std ::endl ; std ::string hello="heheda ollvm" ; if (hello.length()>10 ){ hello="ceshi" ; }else if (hello.length()>30 ){ hello="ollvm" ; }else { hello="fla" ; } std ::cout << hello.c_str() << std ::endl ; return 0 ; }
然后在ollvm的混淆处手动打个日志。看看混淆的目标函数是什么
1 2 3 4 5 void bogus (Function &F) errs() << "bcf: Started on function " << F.getName() << "\n" ; ... ... }
接着编译一下我们的测试例子
clang++ -mllvm -bcf main.cpp
编译结果如下,并没有看到对我们的main函数进行混淆处理。然后我们再测试下clang的。
1 2 bcf: Started on function __cxx_global_var_init bcf: Started on function _GLOBAL__sub_I_main.cpp
clang -mllvm -bcf main.c
编译结果如下,有对我们的main函数进行混淆
1 bcf: Started on function main
那么可以看出区别了。当我们是对c++的项目进行混淆时。要避免需要保护的代码在主函数中。因此,我们再修改下上面的测试代码
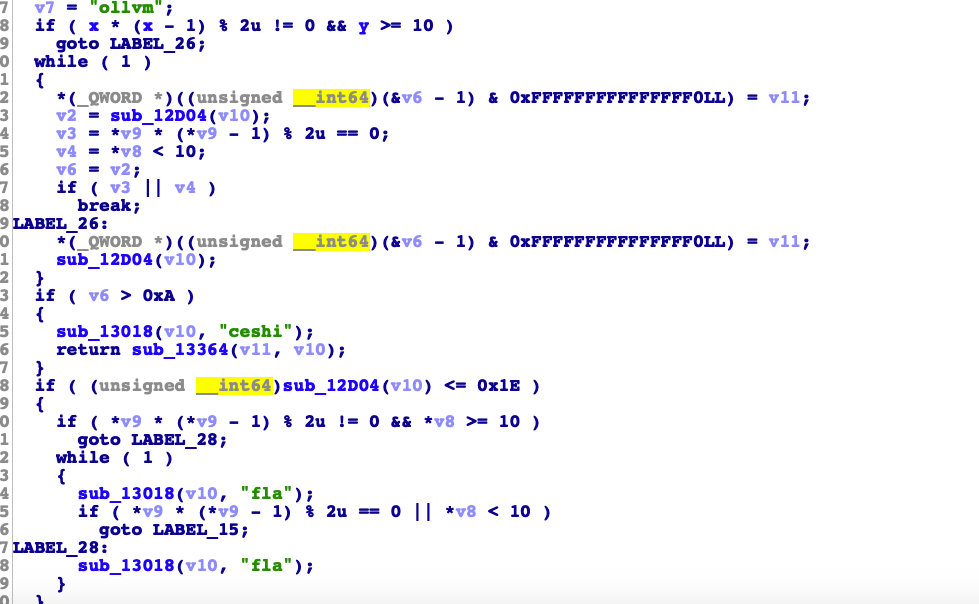
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> std ::string calcKey (std ::string data) if (data.length()>10 ){ data="ceshi" ; }else if (data.length()>30 ){ data="ollvm" ; }else { data="fla" ; } return data; } extern "C" JNIEXPORT jstring JNICALLJava_com_example_ollvmdemo2_MainActivity_stringFromJNI( JNIEnv *env, jobject ) { std ::string hello = "Hello from C++" ; hello=calcKey(hello); return env->NewStringUTF(hello.c_str()); }
那么再进行一次混淆。结果如下。
我们再看看calcKey里面想要保护的代码是否有混淆
到这里准备的案例程序ok了。接着我们开始还原这个虚假分支的混淆。首先我们需要知道这个函数中哪些汇编执行了。所以我们要trace打印每一句执行了的汇编代码地址。
4、使用unidbg模拟执行so 先贴上大佬的github地址:https://github.com/zhkl0228/unidbg
然后先用unidbg把我们的so给模拟执行起来。下面贴上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class BcfTest private final AndroidEmulator emulator;private final VM vm;private final DvmClass mainActivityDvm;public static void main (String[] args) BcfTest bcfTest = new BcfTest(); bcfTest.call_calckey(); } private BcfTest () emulator = AndroidEmulatorBuilder .for64Bit() .build(); Memory memory = emulator.getMemory(); LibraryResolver resolver = new AndroidResolver(23 ); memory.setLibraryResolver(resolver); vm = emulator.createDalvikVM(null ); vm.setVerbose(false ); mainActivityDvm = vm.resolveClass("com/example/ollvmdemo2/MainActivity" ); DalvikModule dm = vm.loadLibrary(new File("unidbg-android/src/test/resources/example_binaries/ollvm_bcf/libnative-lib.so" ), false ); dm.callJNI_OnLoad(emulator); } private void call_calckey () StringObject res = mainActivityDvm.callStaticJniMethodObject(emulator, "stringFromJNI()Ljava/lang/String;" ); System.out.println(res.toString()); }
执行结果是直接显示ceshi。接着我们需要把这个函数执行过程中的每个执行的汇编地址打印一下。
首先找到calcKey函数的起始位置0x124CC以及函数大小0x838
接着给我们之前的代码加上一个tracecode监控。直接修改那个调用函数。在调用前先挂上监控
1 2 3 4 5 6 7 8 9 10 11 12 private void call_calckey () emulator.getBackend().hook_add_new(new CodeHook() { @Override public void hook (Backend backend, long address, int size, Object user) System.out.println(String.format("0x%x" ,address-0x40000000 )); } },0x400124CC ,0x400124CC +0x838 ,null ); StringObject res = mainActivityDvm.callStaticJniMethodObject(emulator, "stringFromJNI()Ljava/lang/String;" ); System.out.println(res.toString()); }
执行完成后得到如下结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 0x124cc 0x124d0 0x124d4 0x124d8 0x124dc 0x124e0 0x124e4 0x124e8 0x124ec 0x124f0 0x124f4 0x124f8 0x124fc 0x12500 0x12504 0x12508 0x1250c 0x12510 0x12514 0x12518 0x1251c 0x12520 0x12524 0x12528 0x1252c 0x12530 0x12534 0x12538 0x12540 0x12544 0x12548 0x1254c 0x12550 0x12554 0x12558 0x1255c 0x12560 0x12564 0x12568 0x12d04 0x1256c 0x12570 0x12574 0x12578 0x1257c 0x12580 0x12584 0x12588 0x1258c 0x12590 0x12594 0x12598 0x1259c 0x125a0 0x125a4 0x125a8 0x125ac 0x125b4 0x125b8 0x125bc 0x125c0 0x125c4 0x125c8 0x125cc 0x125d0 0x12b54 0x12b58 0x12b5c 0x12b60 0x12b64 0x12b68
这里的汇编地址就都是确定有执行到的了。
5、idapython去虚假指令 上面获取到执行了的汇编地址。接下来我们用ida来执行py脚本把执行的部分进行高亮。并且将这个函数范围中的未执行的部分代码修改成nop。改成nop之后ida就不会把未执行的汇编解析出来了。这里可以直接使用idapython,也可以用对idapython进行包装的库。这里的例子用的sark来进行处理。https://github.com/tmr232/Sark
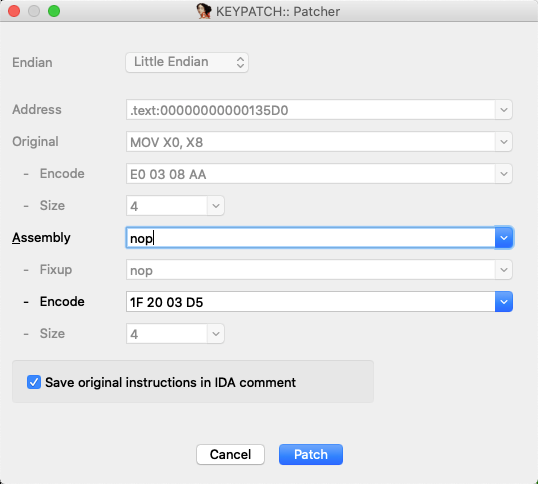
用ida的插件keypatch看了下nop的对应字节是1f 20 03 d5
下面附上py代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import sarkimport idcimport sysdef patch_code (addr,code ): for i in range(len(code)): idc.patch_byte(addr+i,code[i]) def nop (addr ): nop_code=[0x1f ,0x20 ,0x03 ,0xd5 ] patch_code(addr,nop_code) def main (): logfilename="/Volumes/mac_disk/src/python_project/idapythonDemo/ollvm_bcf.log" start=0x124CC end=0x124CC +0x838 addrs=[] with open(logfilename,"r" ) as logfile: lines=logfile.readlines() for line in lines: addrs.append(int(line.replace("\n" ,"" ),16 )) for addr in addrs: line=sark.line.Line(addr) line.color=0x00ffff funcLines=sark.lines(start,end) for line in funcLines: if line.type=="code" : if line.color!=0x00ffff : nop(line.ea) if __name__=="__main__" : main()
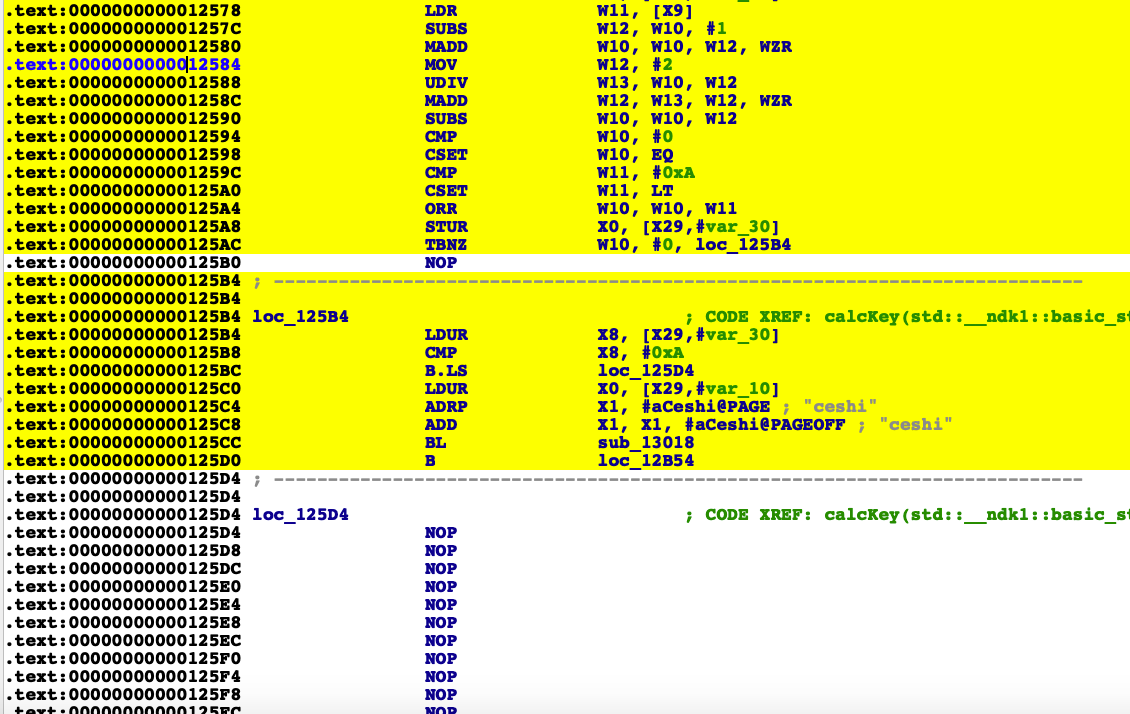
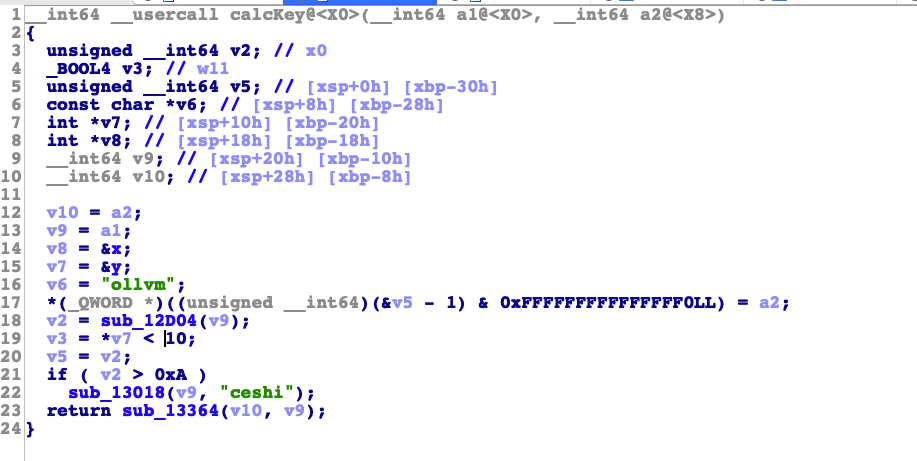
最后ida执行脚本一下。下面附上处理后的效果图
然后看看F5解析出来的变成什么样子了