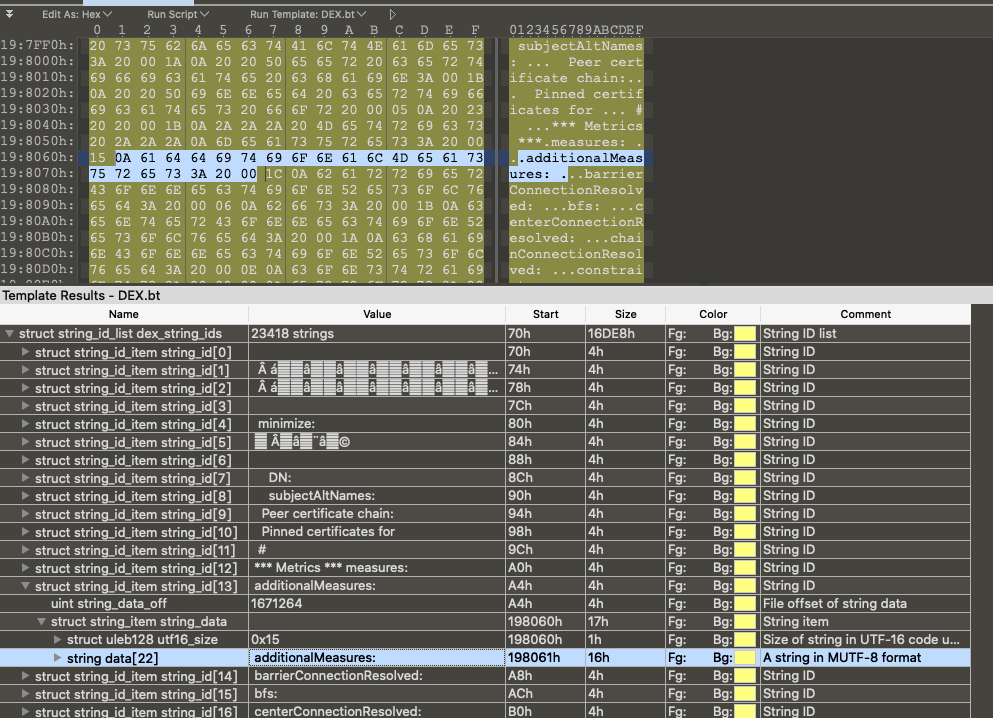
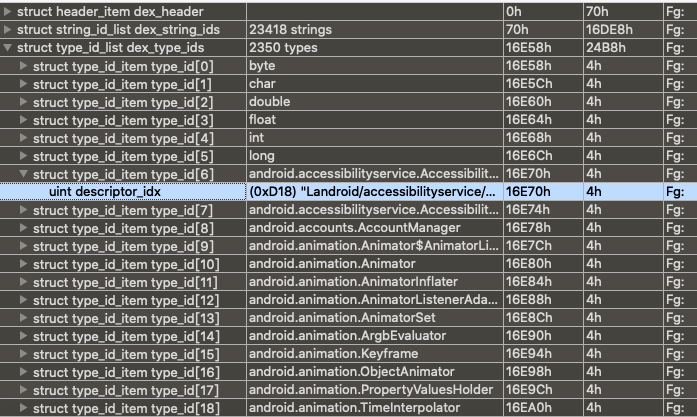
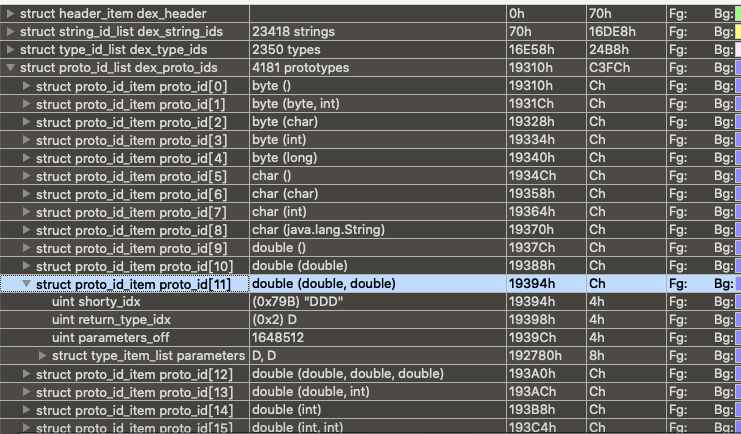
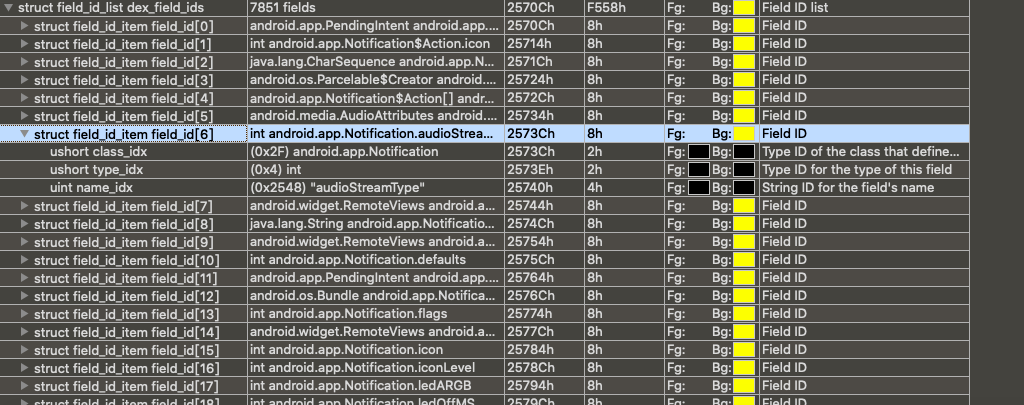
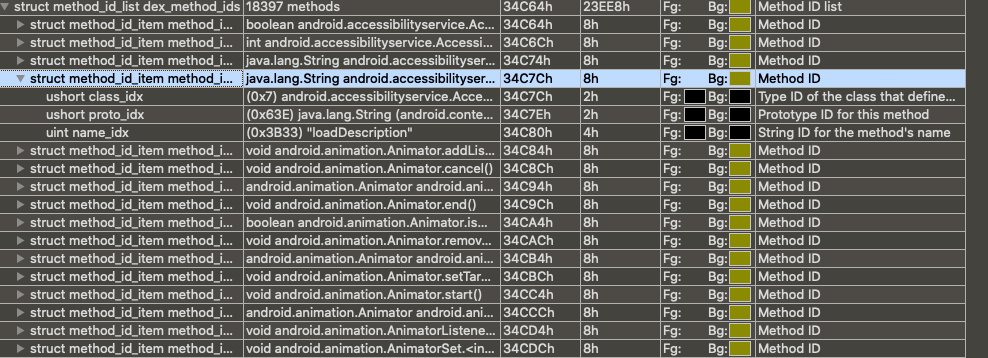
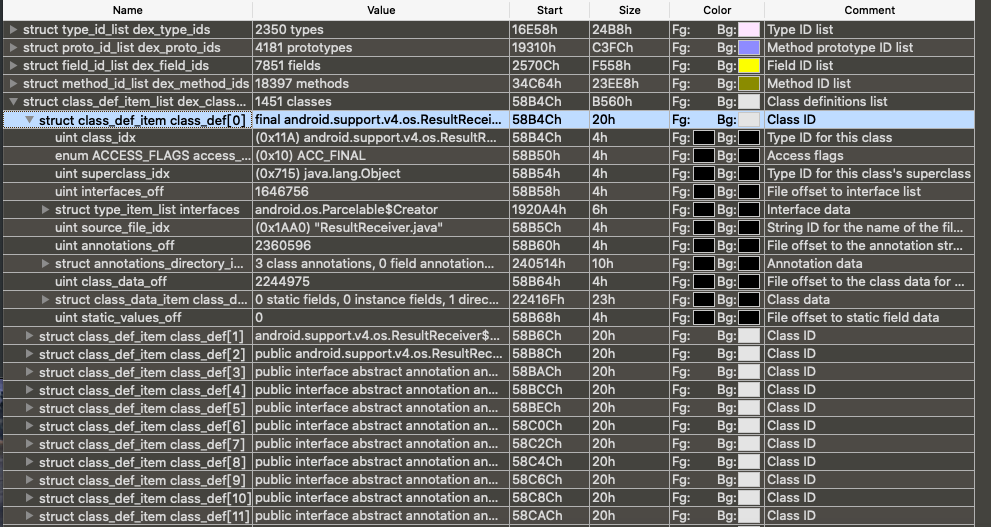
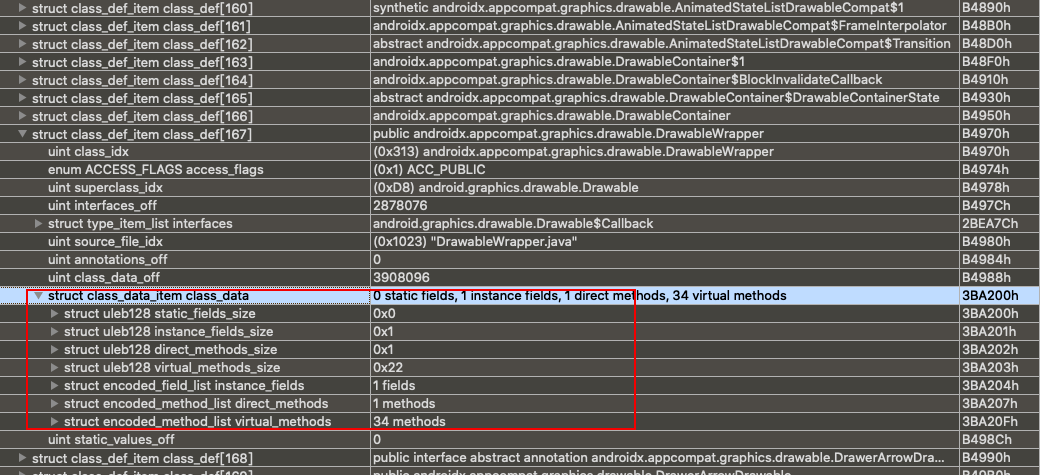
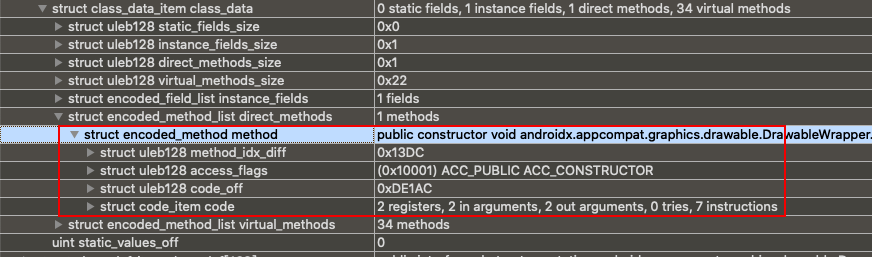
/* * These are mapped out of the "auxillary" section, and may not be * included in the file. */ const DexClassLookup* pClassLookup; constvoid* pRegisterMapPool; // RegisterMapClassPool
/* points to start of DEX file data */ const u1* baseAddr;
/* track memory overhead for auxillary structures */ int overhead;
/* additional app-specific data structures associated with the DEX */ //void* auxData; };
booldvmContinueOptimization(int fd, off_t dexOffset, long dexLength, constchar* fileName, u4 modWhen, u4 crc, bool isBootstrap) { ... /* 简答的检查下文件是否合法 */ if (dexLength < (int) sizeof(DexHeader)) { ALOGE("too small to be DEX"); returnfalse; } if (dexOffset < (int) sizeof(DexOptHeader)) { ALOGE("not enough room for opt header"); returnfalse; }
bool result = false;
/* * Drop this into a global so we don't have to pass it around. We could * also add a field to DexFile, but since it only pertains to DEX * creation that probably doesn't make sense. */ gDvm.optimizingBootstrapClass = isBootstrap;
if (success) { DvmDex* pDvmDex = NULL; u1* dexAddr = ((u1*) mapAddr) + dexOffset; /* 验证odex文件 */ if (dvmDexFileOpenPartial(dexAddr, dexLength, &pDvmDex) != 0) { ALOGE("Unable to create DexFile"); success = false; } else { /* * If configured to do so, generate register map output * for all verified classes. The register maps were * generated during verification, and will now be serialized. * 填充辅助数据区的结构 */ if (gDvm.generateRegisterMaps) { pRegMapBuilder = dvmGenerateRegisterMaps(pDvmDex); if (pRegMapBuilder == NULL) { ALOGE("Failed generating register maps"); success = false; } }
/* 字节排序 */ if (dexSwapAndVerify(addr, len) != 0) goto bail;
/* * 创建dexfile结构 */ if (dvmDexFileOpenPartial(addr, len, &pDvmDex) != 0) { ALOGE("Unable to create DexFile"); goto bail; }
/* * Create the class lookup table. This will eventually be appended * to the end of the .odex. * * We create a temporary link from the DexFile for the benefit of * class loading, below. */ pClassLookup = dexCreateClassLookup(pDvmDex->pDexFile); if (pClassLookup == NULL) goto bail; pDvmDex->pDexFile->pClassLookup = pClassLookup;
/* * If we're not going to attempt to verify or optimize the classes, * there's no value in loading them, so bail out early. */ if (!doVerify && !doOpt) { result = true; goto bail; }
prepWhen = dvmGetRelativeTimeUsec();
/* * Load all classes found in this DEX file. If they fail to load for * some reason, they won't get verified (which is as it should be). * 加载dex中的所有类 */ if (!loadAllClasses(pDvmDex)) goto bail; loadWhen = dvmGetRelativeTimeUsec();
/* * Create a data structure for use by the bytecode optimizer. * We need to look up methods in a few classes, so this may cause * a bit of class loading. We usually do this during VM init, but * for dexopt on core.jar the order of operations gets a bit tricky, * so we defer it to here. */ if (!dvmCreateInlineSubsTable()) goto bail;
/* * Verify and optimize all classes in the DEX file (command-line * options permitting). * * This is best-effort, so there's really no way for dexopt to * fail at this point. * 真正处理验证工作的函数 */ verifyAndOptimizeClasses(pDvmDex->pDexFile, doVerify, doOpt); verifyOptWhen = dvmGetRelativeTimeUsec(); ... }
DexFile* dexFileParse(const u1* data, size_t length, int flags) { ... if (flags & kDexParseVerifyChecksum) { /* 验证dex文件中的checksum字段 */ u4 adler = dexComputeChecksum(pHeader); if (adler != pHeader->checksum) { ALOGE("ERROR: bad checksum (%08x vs %08x)", adler, pHeader->checksum); if (!(flags & kDexParseContinueOnError)) goto bail; } else { ALOGV("+++ adler32 checksum (%08x) verified", adler); }
const DexOptHeader* pOptHeader = pDexFile->pOptHeader; if (pOptHeader != NULL) { /* 验证odex文件中的checksum */ adler = dexComputeOptChecksum(pOptHeader); if (adler != pOptHeader->checksum) { ALOGE("ERROR: bad opt checksum (%08x vs %08x)", adler, pOptHeader->checksum); if (!(flags & kDexParseContinueOnError)) goto bail; } else { ALOGV("+++ adler32 opt checksum (%08x) verified", adler); } } }
/* * Verify the SHA-1 digest. (Normally we don't want to do this -- * the digest is used to uniquely identify the original DEX file, and * can't be computed for verification after the DEX is byte-swapped * and optimized.) */ if (kVerifySignature) { unsignedchar sha1Digest[kSHA1DigestLen]; constint nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum) + kSHA1DigestLen; //signature的验证 dexComputeSHA1Digest(data + nonSum, length - nonSum, sha1Digest); if (memcmp(sha1Digest, pHeader->signature, kSHA1DigestLen) != 0) { char tmpBuf1[kSHA1DigestOutputLen]; char tmpBuf2[kSHA1DigestOutputLen]; ALOGE("ERROR: bad SHA1 digest (%s vs %s)", dexSHA1DigestToStr(sha1Digest, tmpBuf1), dexSHA1DigestToStr(pHeader->signature, tmpBuf2)); if (!(flags & kDexParseContinueOnError)) goto bail; } else { ALOGV("+++ sha1 digest verified"); } } ... }
/* all classes are loaded into the bootstrap class loader */ clazz = dvmLookupClass(classDescriptor, NULL, false); if (clazz != NULL) { //处理单个类的验证和优化 verifyAndOptimizeClass(pDexFile, clazz, pClassDef, doVerify, doOpt);
} else { // TODO: log when in verbose mode ALOGV("DexOpt: not optimizing unavailable class '%s'", classDescriptor); } } }
/* * 验证 */ if (doVerify) { if (dvmVerifyClass(clazz)) { /* * Set the "is preverified" flag in the DexClassDef. We * do it here, rather than in the ClassObject structure, * because the DexClassDef is part of the odex file. */ assert((clazz->accessFlags & JAVA_FLAGS_MASK) == pClassDef->accessFlags); ((DexClassDef*)pClassDef)->accessFlags |= CLASS_ISPREVERIFIED; verified = true; } else { // TODO: log when in verbose mode ALOGV("DexOpt: '%s' failed verification", classDescriptor); } } /* 优化 */ if (doOpt) { bool needVerify = (gDvm.dexOptMode == OPTIMIZE_MODE_VERIFIED || gDvm.dexOptMode == OPTIMIZE_MODE_FULL); if (!verified && needVerify) { ALOGV("DexOpt: not optimizing '%s': not verified", classDescriptor); } else { dvmOptimizeClass(clazz, false);
/* set the flag whether or not we actually changed anything */ ((DexClassDef*)pClassDef)->accessFlags |= CLASS_ISOPTIMIZED; } } }
if (dvmIsClassVerified(clazz)) { ALOGD("Ignoring duplicate verify attempt on %s", clazz->descriptor); returntrue; } //遍历所有直接方法进行验证 for (i = 0; i < clazz->directMethodCount; i++) { if (!verifyMethod(&clazz->directMethods[i])) { LOG_VFY("Verifier rejected class %s", clazz->descriptor); returnfalse; } } //遍历所有虚方法进行验证 for (i = 0; i < clazz->virtualMethodCount; i++) { if (!verifyMethod(&clazz->virtualMethods[i])) { LOG_VFY("Verifier rejected class %s", clazz->descriptor); returnfalse; } }
staticboolverifyMethod(Method* meth) { bool result = false;
/* * Verifier state blob. Various values will be cached here so we * can avoid expensive lookups and pass fewer arguments around. */ VerifierData vdata; #if 1 // ndef NDEBUG memset(&vdata, 0x99, sizeof(vdata)); #endif
/* * If there aren't any instructions, make sure that's expected, then * exit successfully. Note: for native methods, meth->insns gets set * to a native function pointer on first call, so don't use that as * an indicator. */ if (vdata.insnsSize == 0) { if (!dvmIsNativeMethod(meth) && !dvmIsAbstractMethod(meth)) { LOG_VFY_METH(meth, "VFY: zero-length code in concrete non-native method"); goto bail; }
goto success; }
/* * Sanity-check the register counts. ins + locals = registers, so make * sure that ins <= registers. */ if (meth->insSize > meth->registersSize) { LOG_VFY_METH(meth, "VFY: bad register counts (ins=%d regs=%d)", meth->insSize, meth->registersSize); goto bail; }
/* * Allocate and populate an array to hold instruction data. * * TODO: Consider keeping a reusable pre-allocated array sitting * around for smaller methods. */ vdata.insnFlags = (InsnFlags*) calloc(vdata.insnsSize, sizeof(InsnFlags)); if (vdata.insnFlags == NULL) goto bail;
/* * Compute the width of each instruction and store the result in insnFlags. * Count up the #of occurrences of certain opcodes while we're at it. */ if (!computeWidthsAndCountOps(&vdata)) goto bail;
/* * Allocate a map to hold the classes of uninitialized instances. */ vdata.uninitMap = dvmCreateUninitInstanceMap(meth, vdata.insnFlags, vdata.newInstanceCount); if (vdata.uninitMap == NULL) goto bail;
/* * Set the "in try" flags for all instructions guarded by a "try" block. * Also sets the "branch target" flag on exception handlers. */ if (!scanTryCatchBlocks(meth, vdata.insnFlags)) goto bail;
/* * Perform static instruction verification. Also sets the "branch * target" flags. * 验证方法中指令的数量以及正确性 */ if (!verifyInstructions(&vdata)) goto bail;
/* * Do code-flow analysis. * * We could probably skip this for a method with no registers, but * that's so rare that there's little point in checking. * 验证代码流的正确性 */ if (!dvmVerifyCodeFlow(&vdata)) { //ALOGD("+++ %s failed code flow", meth->name); goto bail; }
voiddvmOptimizeClass(ClassObject* clazz, bool essentialOnly) { int i;
for (i = 0; i < clazz->directMethodCount; i++) { optimizeMethod(&clazz->directMethods[i], essentialOnly); } for (i = 0; i < clazz->virtualMethodCount; i++) { optimizeMethod(&clazz->virtualMethods[i], essentialOnly); } }
/* * Each instruction may have: * - "volatile" replacement * - may be essential or essential-on-SMP * - correctness replacement * - may be essential or essential-on-SMP * - performance replacement * - always non-essential * * Replacements are considered in the order shown, and the first * match is applied. For example, iget-wide will convert to * iget-wide-volatile rather than iget-wide-quick if the target * field is volatile. */
/* * essential substitutions: * {iget,iput,sget,sput}-wide --> {op}-wide-volatile * invoke-direct[/range] --> invoke-object-init/range * * essential-on-SMP substitutions: * {iget,iput,sget,sput}-* --> {op}-volatile * return-void --> return-void-barrier * * non-essential substitutions: * {iget,iput}-* --> {op}-quick * * TODO: might be time to merge this with the other two switches */ switch (opc) { case OP_IGET: case OP_IGET_BOOLEAN: case OP_IGET_BYTE: case OP_IGET_CHAR: case OP_IGET_SHORT: quickOpc = OP_IGET_QUICK; if (forSmp) volatileOpc = OP_IGET_VOLATILE; goto rewrite_inst_field; case OP_IGET_WIDE: quickOpc = OP_IGET_WIDE_QUICK; volatileOpc = OP_IGET_WIDE_VOLATILE; goto rewrite_inst_field; case OP_IGET_OBJECT: quickOpc = OP_IGET_OBJECT_QUICK; if (forSmp) volatileOpc = OP_IGET_OBJECT_VOLATILE; goto rewrite_inst_field; case OP_IPUT: case OP_IPUT_BOOLEAN: case OP_IPUT_BYTE: case OP_IPUT_CHAR: case OP_IPUT_SHORT: quickOpc = OP_IPUT_QUICK; if (forSmp) volatileOpc = OP_IPUT_VOLATILE; goto rewrite_inst_field; case OP_IPUT_WIDE: quickOpc = OP_IPUT_WIDE_QUICK; volatileOpc = OP_IPUT_WIDE_VOLATILE; goto rewrite_inst_field; case OP_IPUT_OBJECT: quickOpc = OP_IPUT_OBJECT_QUICK; if (forSmp) volatileOpc = OP_IPUT_OBJECT_VOLATILE; /* fall through */ rewrite_inst_field: if (essentialOnly) quickOpc = OP_NOP; /* if essential-only, no "-quick" sub */ if (quickOpc != OP_NOP || volatileOpc != OP_NOP) rewriteInstField(method, insns, quickOpc, volatileOpc); break;
case OP_SGET: case OP_SGET_BOOLEAN: case OP_SGET_BYTE: case OP_SGET_CHAR: case OP_SGET_SHORT: if (forSmp) volatileOpc = OP_SGET_VOLATILE; goto rewrite_static_field; case OP_SGET_WIDE: volatileOpc = OP_SGET_WIDE_VOLATILE; goto rewrite_static_field; case OP_SGET_OBJECT: if (forSmp) volatileOpc = OP_SGET_OBJECT_VOLATILE; goto rewrite_static_field; case OP_SPUT: case OP_SPUT_BOOLEAN: case OP_SPUT_BYTE: case OP_SPUT_CHAR: case OP_SPUT_SHORT: if (forSmp) volatileOpc = OP_SPUT_VOLATILE; goto rewrite_static_field; case OP_SPUT_WIDE: volatileOpc = OP_SPUT_WIDE_VOLATILE; goto rewrite_static_field; case OP_SPUT_OBJECT: if (forSmp) volatileOpc = OP_SPUT_OBJECT_VOLATILE; /* fall through */ rewrite_static_field: if (volatileOpc != OP_NOP) rewriteStaticField(method, insns, volatileOpc); break;
case OP_INVOKE_DIRECT: case OP_INVOKE_DIRECT_RANGE: if (!rewriteInvokeObjectInit(method, insns)) { /* may want to try execute-inline, below */ matched = false; } break; case OP_RETURN_VOID: if (needRetBar) rewriteReturnVoid(method, insns); break; default: matched = false; break; }
/* * non-essential substitutions: * invoke-{virtual,direct,static}[/range] --> execute-inline * invoke-{virtual,super}[/range] --> invoke-*-quick */ if (!matched && !essentialOnly) { switch (opc) { case OP_INVOKE_VIRTUAL: if (!rewriteExecuteInline(method, insns, METHOD_VIRTUAL)) { rewriteVirtualInvoke(method, insns, OP_INVOKE_VIRTUAL_QUICK); } break; case OP_INVOKE_VIRTUAL_RANGE: if (!rewriteExecuteInlineRange(method, insns, METHOD_VIRTUAL)) { rewriteVirtualInvoke(method, insns, OP_INVOKE_VIRTUAL_QUICK_RANGE); } break; case OP_INVOKE_SUPER: rewriteVirtualInvoke(method, insns, OP_INVOKE_SUPER_QUICK); break; case OP_INVOKE_SUPER_RANGE: rewriteVirtualInvoke(method, insns, OP_INVOKE_SUPER_QUICK_RANGE); break; case OP_INVOKE_DIRECT: rewriteExecuteInline(method, insns, METHOD_DIRECT); break; case OP_INVOKE_DIRECT_RANGE: rewriteExecuteInlineRange(method, insns, METHOD_DIRECT); break; case OP_INVOKE_STATIC: rewriteExecuteInline(method, insns, METHOD_STATIC); break; case OP_INVOKE_STATIC_RANGE: rewriteExecuteInlineRange(method, insns, METHOD_STATIC); break; default: /* nothing to do for this instruction */ ; } }